RAG项目(AI 面试助手) 概述 每个项目笔记包含:
全局认知:3分钟讲清项目全貌
业务架构,从用户痛点到解决方案
技术架构,分层结构到数据流向
电梯演讲,业务价值+技术亮点+我的认知)
模块拆解:看着项目前端说清楚系统内部如何协作
模块依赖,讲清楚核心模块以及它们之间的调用关系
接口清单,列举关键方法,清楚入参/出参/异常
时序图,讲清楚核心场景的完整调用链
代码深入:解释关键设计的决策
精读配置类(线程池/超时/连接池参数及选型理由)
精读核心算法(一致性哈希/ID生成/幂等实现)
精读异常处理(降级/重试/雪崩防护策略)
改造验证:证明动手能力和抗压场景思路
测试幂等、降级逻辑
换数据库或缓存模式,对比差异
压力测试找瓶颈+准备”如果QPS翻10倍”的扩容方案和应对方案
功能测试,如果让你添加某个功能,你如何改动
知识体系:形成方法论
横向对比同类系统,分析优劣
准备灵魂对比,最大难点/重新开发怎么改/相比竞品的优势
全局认知 业务架构 用户痛点:
建立质量难把控 , ToC 求职者不清楚自己简历的问题,ToB HR 筛选简历效率低面试准备无针对性 ,通用面试题与实际简历不匹配,缺乏个性化练习技术文档检索难 ,企业/项目内部知识分散,查询答案耗时(这里可以把简历分析报告联动到RAG里去)
解决方案:AI 面试助手
简历管理(多格式上传、AI分析评分、改进建议、PDF报告导出)
模拟面试(AI 智能出题(可改进为基于面经出题 )、实时问答交互、答案智能评估、面试报告生成)
知识库问答(文档上传与向量化、RAG检索增强、多轮对话问答、SSE流式响应)
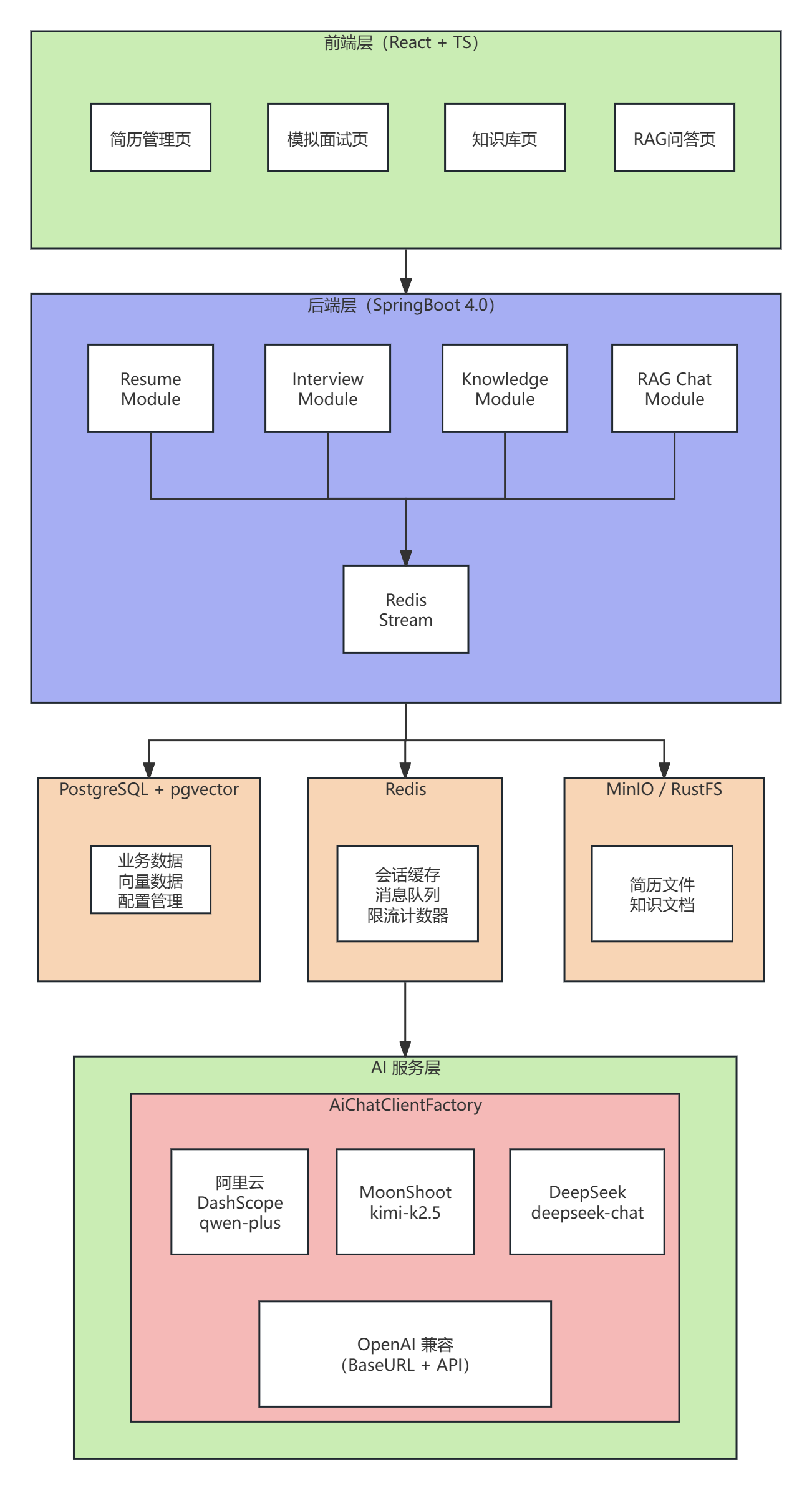
技术架构 核心数据流向
场景
数据流向
关键技术
简历上传分析
上传 → 文件解析(Tika) → MinIO存储 → Stream入队 → AI分析 → 结果入库
异步解耦、文件Hash去重
模拟面试
创建会话(Redis缓存) → AI出题 → 答题 → 分批评估 → 生成报告
分批处理防Token溢出
RAG问答
Query向量化 → pgvector相似度检索 → 上下文构建 → LLM生成 → SSE流式返回
RAG检索增强
电梯演讲
开场(10秒)
“我独立开发了一个智能 AI 面试助手平台,帮助求职者和 HR 解决简历评估与面试准备的痛点。”
业务价值(50秒)
“平台提供三大核心能力:
简历智能分析 — 上传简历后 AI 自动评分并给出改进建议,支持 PDF 报告导出
个性化模拟面试 — 基于简历内容生成针对性面试题,支持多轮追问和答案评估
RAG 知识库问答 — 技术文档向量化存储,实现检索增强的智能问答
解决的核心痛点是:简历质量难把控、面试准备缺乏针对性、技术文档检索困难。”
技术亮点(90秒)
“技术选型上采用 Spring Boot 4.0 + Java 21 + Spring AI 2.0 构建后端,前端用 React + TypeScript。四个核心亮点:
异步解耦设计 — 简历分析、知识库向量化等耗时操作采用 Redis Stream 异步处理,避免 AI 调用阻塞用户请求,支持任务失败自动重试
RAG 检索增强 — 基于 pgvector 实现向量检索,无需引入额外向量数据库;动态调整 TopK 和相似度阈值,自动扩展提高召回率
流式交互体验 — 基于 SSE 实现打字机效果的流式响应,减少用户等待焦虑
稳定性保障 — 面试评估采用分批处理策略(每批8题),规避大模型 Token 溢出风险;注解式限流组件防止 API 滥用”
个人认知(30秒)
“通过这个项目,我对 AI 应用架构 有了体系化认知:从 Prompt 工程到 RAG 优化,从异步任务设计到流式响应实现。最深刻的体会是 ‘AI 能力需要工程化封装’ —— 大模型只是基础,真正交付价值需要完善的错误处理、状态管理和用户体验设计。”
💡 面试 Tips
如果面试官追问”项目来源” → 个人向的ToC,简历筛选向的ToB
准备几个数字:
• 向量维度:1024 维(text-embedding-v3)
• 面试评估分批:每批 8 题
• 支持格式:PDF/DOCX/DOC/TXT/MD
可以提到的扩展点:
• 支持对接 Ollama 本地部署(成本优化)
• 面试会话支持断点续面(Redis 缓存 24h)
• 文件 Hash 去重避免重复处理
模块拆解 总览 1 2 3 4 5 6 7 8 9 10 ┌─────────────────────────────────────────────────────────────────────────────┐ │ 智能 AI 面试助手平台 │ ├─────────────────┬─────────────────┬─────────────────┬───────────────────────┤ │ 📄 简历管理 │ 🎤 模拟面试 │ 📚 知识库 │ ⚙️ 系统设置 │ ├─────────────────┼─────────────────┼─────────────────┼───────────────────────┤ │ Resume Module │ Interview Module│Knowledge Module │ Settings Module │ ├─────────────────┴─────────────────┴─────────────────┴───────────────────────┤ │ 🤖 RAG 问答模块 (跨模块) │ │ RAG Chat Module │ └─────────────────────────────────────────────────────────────────────────────┘
简历管理模块 — 文件上传、解析、AI分析、异步处理
模拟面试模块 — 会话管理、智能出题、答案评估、分批处理
知识库+RAG模块 — 文档向量化、向量检索、多轮对话
系统设置模块 — 多AI平台配置、限流组件
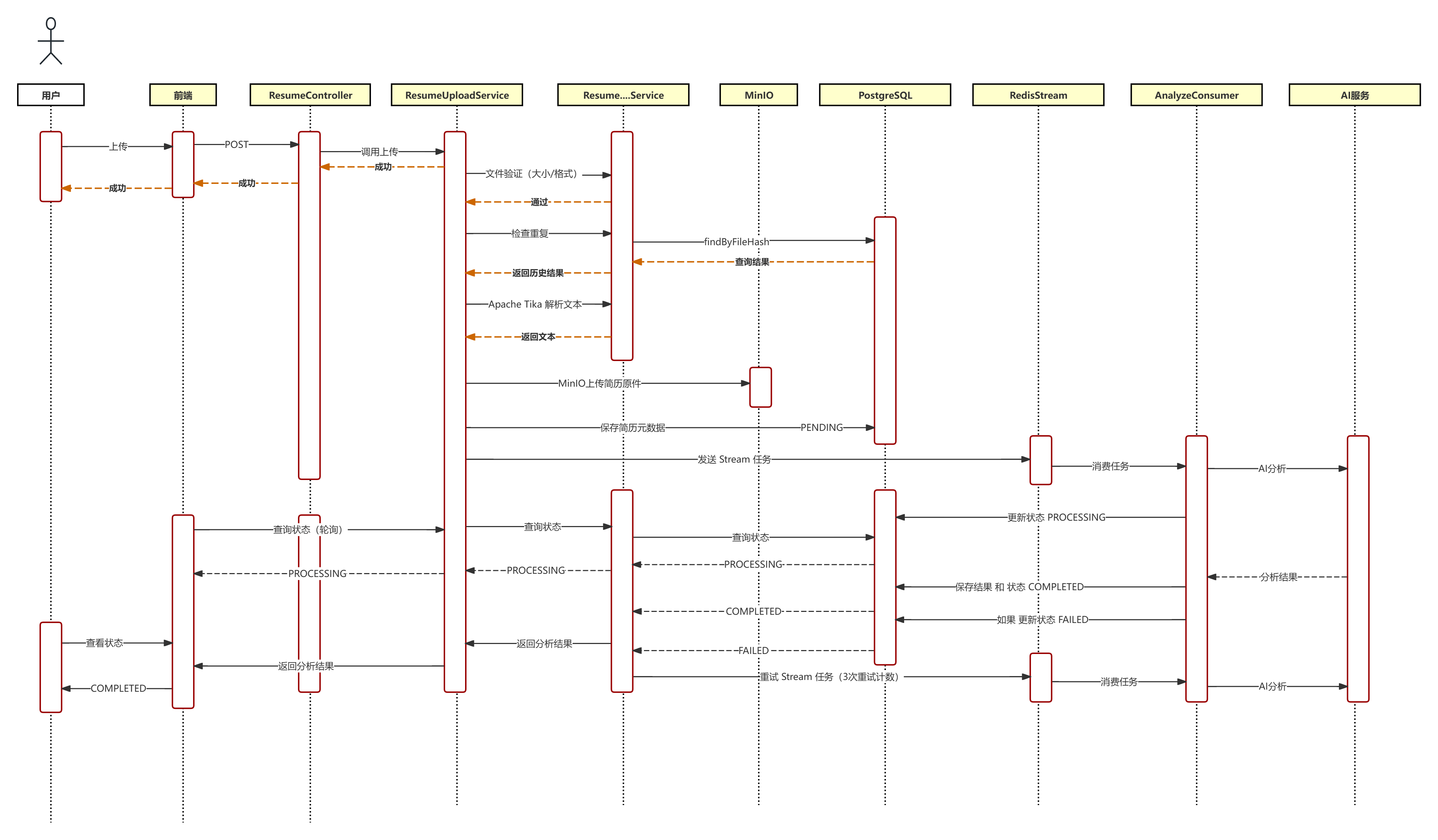
简历管理模块 定位
上传解析:多格式支持、文件验证、重复检测、文本提取
AI分析:智能评分、改进建议、异步处理、失败重试
历史管理:列表查询、详情查看、报告PDF导出、删除管理
支持格式:PDF / DOCX / DOC / TXT / MD
文件限制:最大 10MB
流程(重点) 我来将这个文件内容整理为Markdown格式:
关键技术实现 (面试重点 ★★★)
文件解析 —— Apache Tika
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 private String parseContent (InputStream inputStream) throws ... { AutoDetectParser parser = new AutoDetectParser (); BodyContentHandler handler = new BodyContentHandler (MAX_TEXT_LENGTH); context.set(EmbeddedDocumentExtractor.class, new NoOpEmbeddedDocumentExtractor ()); PDFParserConfig pdfConfig = new PDFParserConfig (); pdfConfig.setSortByPosition(true ); context.set(PDFParserConfig.class, pdfConfig); parser.parse(inputStream, handler, metadata, context); return handler.toString(); }
面试话术: “使用 Apache Tika 实现多格式文档解析时,我遇到了一个生产环境问题——PDF 中的图片被解析成了临时文件路径。解决方案是自定义 NoOpEmbeddedDocumentExtractor 禁用嵌入资源解析,只提取纯文本,同时设置 SortByPosition 优化多栏布局的文本顺序。”
异步处理 —— Redis Stream
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Component public class AnalyzeStreamProducer { public void sendAnalyzeTask (Long resumeId, String content, ...) { Map<String, String> message = new HashMap <>(); message.put("resumeId" , resumeId.toString()); message.put("content" , content); redisService.streamAdd(RESUME_ANALYZE_STREAM_KEY, message, STREAM_MAX_LEN); } } @Component public class AnalyzeStreamConsumer extends AbstractStreamConsumer <AnalyzePayload> { @Override protected void processBusiness (AnalyzePayload payload) { if (!resumeRepository.existsById(payload.resumeId())) { return ; } ResumeAnalysisResponse analysis = gradingService.analyzeResume(...); persistenceService.saveAnalysis(resume, analysis); } @Override protected void retryMessage (AnalyzePayload payload, int retryCount) { if (retryCount < MAX_RETRY_COUNT) { } } }
为什么选择 Redis Stream 而不是 MQ?
项目规模: 不需要引入 Kafka/RabbitMQ 重量级组件功能足够: 支持持久化、消费者组、ACK 确认架构精简: 复用已有的 Redis 基础设施
限流保护 —— Redis + Lua 滑动窗口
1 2 3 4 5 6 7 8 9 10 11 12 @RestController public class ResumeController { @PostMapping("/api/resumes/upload") @RateLimit( dimensions = {RateLimit.Dimension.GLOBAL, RateLimit.Dimension.IP}, count = 5, // 5次 interval = 1, timeUnit = TimeUnit.MINUTES // 每1分钟 ) public Result<?> uploadAndAnalyze(...) { ... } }
Lua 脚本核心逻辑(滑动窗口算法):1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 redis.call('ZREMRANGEBYSCORE' , key, 0 , window_start) local current_count = redis.call('ZCARD' , key)if current_count >= limit then return 0 end redis.call('ZADD' , key, timestamp, unique_id) redis.call('EXPIRE' , key, ttl) return 1
面试亮点 :
滑动窗口 vs 固定窗口: 避免窗口边界突发流量问题
Redis + Lua: 保证原子性,避免竞态条件
多维度组合: 同时支持全局 + IP + 用户级限流
Hash Tag: {className:methodName} 确保 Cluster 模式下同一 Slot
AI 分析 —— 结构化 Prompt + 重试机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @Service public class ResumeGradingService { public ResumeAnalysisResponse analyzeResume (String resumeText, ...) { String systemPrompt = systemPromptTemplate.render(); Map<String, Object> variables = new HashMap <>(); variables.put("resumeText" , resumeText); variables.put("extraInfo" , buildExtraInfo(resumeType, targetPosition)); String userPrompt = userPromptTemplate.render(variables); String systemPromptWithFormat = systemPrompt + "\n\n" + outputConverter.getFormat(); ResumeAnalysisResponseDTO dto = structuredOutputInvoker.invoke( chatClient, systemPromptWithFormat, userPrompt, outputConverter, ErrorCode.RESUME_ANALYSIS_FAILED, "简历分析" , log ); return convertToResponse(dto); } }
Prompt 设计要点:
System Prompt: 定义角色(资深 HR)、评分标准(5维度)、输出格式(JSON Schema)User Prompt: 简历内容 + 补充信息(校招/社招、目标岗位)结构化输出: 使用 BeanOutputConverter 强制 AI 返回 JSON,自动映射到 Java 对象
重复检测 —— 文件 Hash
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Service public class ResumePersistenceService { public Optional<ResumeEntity> findExistingResume (MultipartFile file) { String fileHash = calculateFileHash(file); return resumeRepository.findByFileHash(fileHash); } private String calculateFileHash (MultipartFile file) { try (InputStream is = file.getInputStream()) { return DigestUtils.md5Hex(is); } } }
业务价值: 避免用户重复上传相同简历,浪费 AI 调用成本(每次调用都计费)。
面试重点与话术
高频问题
问题
回答要点
“为什么 AI 分析要异步?”
AI 调用耗时 3-10 秒,同步会阻塞用户请求;异步提升用户体验,支持失败重试;削峰填谷,避免瞬时高并发压垮 AI 服务
“如何保证分析不丢失?”
Redis Stream 持久化;消费者 ACK 确认;失败自动重试(最多3次);支持手动重试 API
“限流是怎么实现的?”
Redis + Lua 滑动窗口;原子操作避免竞态;多维度组合(全局+IP);注解式使用,零侵入
“文件解析遇到过什么问题?”
PDF 图片解析为临时路径问题 → 禁用嵌入资源解析;多栏布局顺序混乱 → SortByPosition;超大文件内存问题 → 限制 5MB
“重复上传怎么处理?”
MD5 Hash 去重;返回历史分析结果;避免重复调用 AI 节约成本
亮点数据(面试加分)
技术细节:
文件解析: Apache Tika 支持 5+ 种格式限流算法: 滑动时间窗口,精度毫秒级重试机制: 最多 3 次,指数退避文本限制: 最大提取 5MB 文本(防止内存溢出)文件限制: 最大 10MB
可能的追问
Q: 如果 AI 服务挂了怎么办?
“Consumer 会捕获异常,标记任务为 FAILED,并保存错误信息。用户可以在前端看到失败状态,点击’重新分析’按钮手动触发重试。同时我们预留了降级策略的扩展点,可以对接本地 Ollama 模型作为备用。”
Q: 上传大文件卡住怎么办?
“前端有上传进度条;后端文件验证优先检查大小(10MB限制),超大会立即返回错误,不会进入后续流程;Tika 解析设置 5MB 文本上限,防止超大文件导致 OOM。”
Q: 如何防止用户刷接口?
“上传接口有 @RateLimit 注解,限制每个 IP 每分钟最多 5 次。使用 Redis + Lua 实现滑动窗口,相比固定窗口更平滑,避免窗口边界突发流量。”
总结图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌─────────────────────────────────────────────────────────────────┐ │ 简历管理模块技术栈 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 文件处理 Apache Tika + 自定义解析优化 │ │ 存储层 MinIO (S3兼容) + PostgreSQL │ │ 缓存/队列 Redis (Hash缓存 + Stream消息队列) │ │ AI 调用 Spring AI + 结构化 Prompt │ │ 限流保护 Redis + Lua 滑动窗口 │ │ 任务调度 Redis Stream Consumer 异步消费 │ │ │ │ 可靠性设计: │ │ ✓ 文件 Hash 去重 ✓ 异步任务状态机 ✓ 失败自动重试 │ │ ✓ 手动重试 API ✓ 注解式限流 ✓ 优雅异常处理 │ │ │ └─────────────────────────────────────────────────────────────────┘
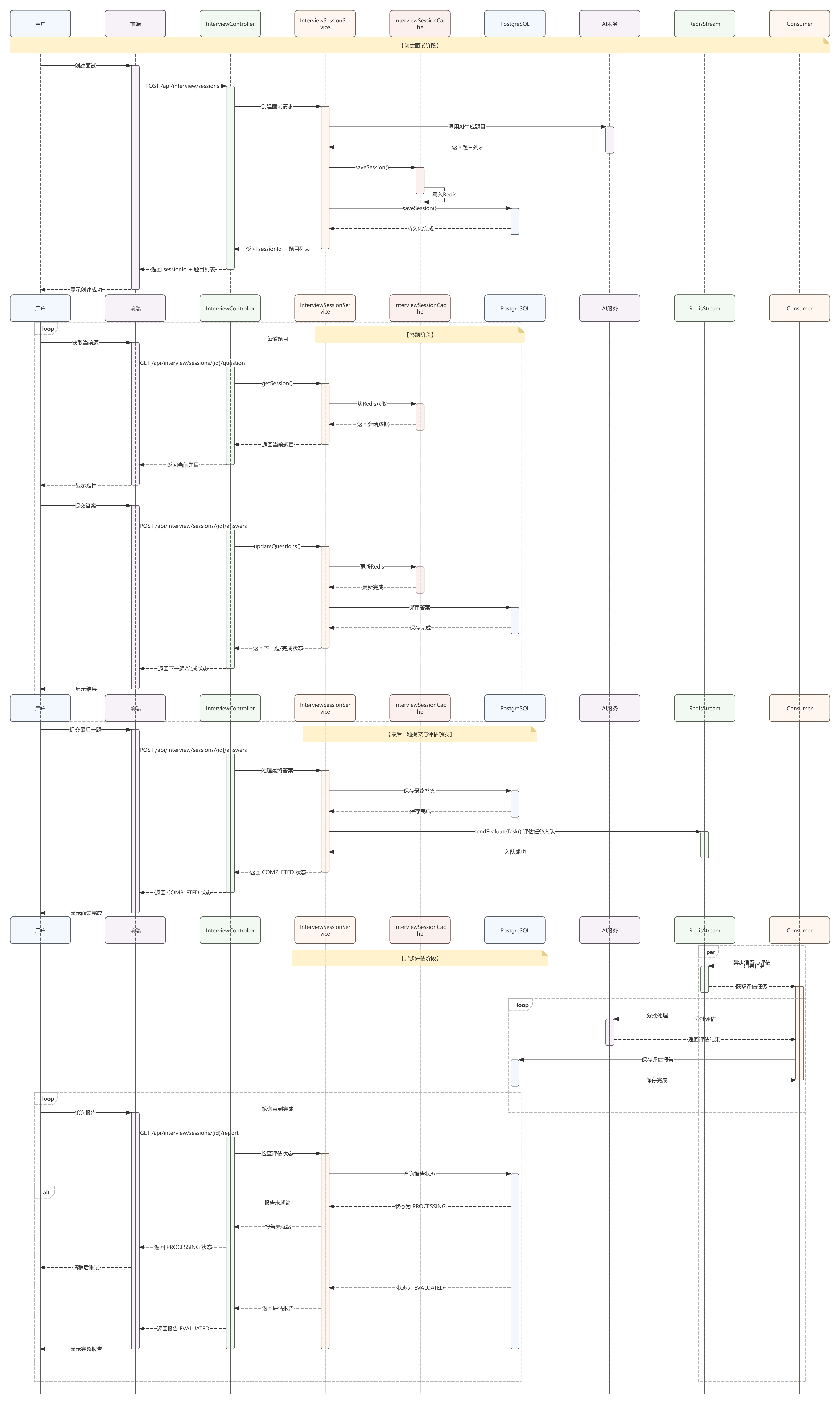
模拟面试 总览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ┌─────────────────────────────────────────────────────────────────┐ │ 模拟面试模块职责边界 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │ │ │ 会话管理 │ │ 题目生成 │ │ 答案评估 │ │ │ ├─────────────┤ ├─────────────┤ ├─────────────┤ │ │ │ • 创建会话 │ │ • AI 智能出题│ │ • 分批评估 │ │ │ │ • 断点续面 │ │ • 追问机制 │ │ • 汇总报告 │ │ │ │ • 状态流转 │ │ • 去重策略 │ │ • 参考答案 │ │ │ │ • 提前交卷 │ │ • 默认兜底 │ │ • PDF导出 │ │ │ └─────────────┘ └─────────────┘ └─────────────┘ │ │ │ │ 核心状态:CREATED → IN_PROGRESS → COMPLETED → EVALUATED │ │ 缓存策略:Redis 24h TTL,支持断点续面 │ └─────────────────────────────────────────────────────────────────┘
流程(重点) 关键技术实现(面试重点 ★★★) 会话管理 —— Redis 缓存优先 + 数据库持久化1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Service public class InterviewSessionService { public InterviewSessionDTO createSession (CreateInterviewRequest request) { Optional<InterviewSessionDTO> unfinishedOpt = findUnfinishedSession(request.resumeId()); if (unfinishedOpt.isPresent()) { return unfinishedOpt.get(); } List<InterviewQuestionDTO> questions = questionService.generateQuestions( request.resumeText(), request.questionCount(), historicalQuestions ); sessionCache.saveSession(sessionId, resumeText, resumeId, questions, 0 , CREATED); persistenceService.saveSession(sessionId, resumeId, questions.size(), questions); return new InterviewSessionDTO (...); } public InterviewSessionDTO getSession (String sessionId) { Optional<CachedSession> cachedOpt = sessionCache.getSession(sessionId); if (cachedOpt.isPresent()) { return toDTO(cachedOpt.get()); } CachedSession restoredSession = restoreSessionFromDatabase(sessionId); return toDTO(restoredSession); } }
面试话术:
“面试会话采用 ‘缓存优先 + 双写策略’。所有状态变更先写 Redis(24h TTL),异步同步到数据库。这样做有两个好处:
性能:答题交互毫秒级响应,不依赖数据库
断点续面:即使 Redis 过期,也能从数据库恢复会话,用户体验不中断”
智能出题 —— 分类配比 + 历史去重 + 追问机制1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 @Service public class InterviewQuestionService { private static final double PROJECT_RATIO = 0.20 ; private static final double MYSQL_RATIO = 0.20 ; private static final double REDIS_RATIO = 0.20 ; private static final double JAVA_BASIC_RATIO = 0.10 ; private static final double JAVA_COLLECTION_RATIO = 0.10 ; private static final double JAVA_CONCURRENT_RATIO = 0.10 ; public List<InterviewQuestionDTO> generateQuestions (String resumeText, int questionCount, List<String> historicalQuestions) { QuestionDistribution distribution = calculateDistribution(questionCount); Map<String, Object> variables = new HashMap <>(); variables.put("historicalQuestions" , String.join("\n" , historicalQuestions)); variables.put("projectCount" , distribution.project); variables.put("mysqlCount" , distribution.mysql); QuestionListDTO dto = structuredOutputInvoker.invoke(...); return convertToQuestions(dto); } private List<InterviewQuestionDTO> convertToQuestions (QuestionListDTO dto) { List<InterviewQuestionDTO> questions = new ArrayList <>(); for (QuestionDTO q : dto.questions()) { questions.add(InterviewQuestionDTO.create(index++, q.question(), type, category, false , null )); List<String> followUps = sanitizeFollowUps(q.followUps()); for (int i = 0 ; i < followUps.size(); i++) { questions.add(InterviewQuestionDTO.create( index++, followUps.get(i), type, buildFollowUpCategory(category, i + 1 ), true , mainQuestionIndex )); } } return questions; } private List<InterviewQuestionDTO> generateDefaultQuestions (int count) { String[][] defaultQuestions = { {"请介绍一下你在简历中提到的最重要的项目..." , "PROJECT" , "项目经历" }, {"MySQL的索引有哪些类型?B+树索引的原理是什么?" , "MYSQL" , "MySQL" }, }; return convertDefaultToDTOs(defaultQuestions, count); } }
面试亮点:
分类配比 :根据后端面试重点,按权重分配各类问题数量历史去重 :传入历史问题列表,Prompt 中明确要求 “不要重复以下历史问题”追问机制 :每个主问题配置 followUpCount 条追问,构建线性追问流优雅降级 :AI 调用失败时返回预设默认问题,保证服务可用性
答案评估 —— 分批处理规避 Token 溢出(核心亮点 ★★★)1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 @Service public class AnswerEvaluationService { @Value("${app.interview.evaluation.batch-size:8}") private int evaluationBatchSize; public InterviewReportDTO evaluateInterview (String sessionId, String resumeText, List<InterviewQuestionDTO> questions) { List<BatchEvaluationResult> batchResults = evaluateInBatches(sessionId, resumeSummary, questions); List<QuestionEvaluationDTO> mergedEvaluations = mergeQuestionEvaluations(batchResults); String fallbackOverallFeedback = mergeOverallFeedback(batchResults); FinalSummaryDTO finalSummary = summarizeBatchResults( sessionId, resumeSummary, questions, mergedEvaluations, fallbackOverallFeedback, ... ); return convertToReport(sessionId, mergedEvaluations, questions, finalSummary); } private List<BatchEvaluationResult> evaluateInBatches (...) { List<BatchEvaluationResult> results = new ArrayList <>(); for (int start = 0 ; start < questions.size(); start += evaluationBatchSize) { int end = Math.min(start + evaluationBatchSize, questions.size()); List<InterviewQuestionDTO> batchQuestions = questions.subList(start, end); EvaluationReportDTO report = evaluateBatch(sessionId, resumeSummary, batchQuestions, start, end); results.add(new BatchEvaluationResult (start, end, report)); } return results; } private EvaluationReportDTO evaluateBatch (...) { String qaRecords = buildQARecords(batchQuestions); return structuredOutputInvoker.invoke( aiChatClientFactory.getChatClient(), systemPromptWithFormat, userPrompt, outputConverter, ... ); } }
面试话术:
“答案评估最大的挑战是 Token 溢出。假设一份简历有 20 道题,每道题的回答平均 500 字,加上简历本身和 Prompt,总 Token 可能超过 8k,超出模型限制。
将问题按每批 8 题分组,每批独立调用 AI 评估
合并各批次的评估结果
再调用一次 AI 对整体表现进行汇总(strengths、improvements、overallFeedback)
会话缓存设计 —— Redis 数据结构Redis Key 设计:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ┌─────────────────────────────────────────────────────────────────┐ │ interview:session:{sessionId} │ │ ├─ Hash 存储 CachedSession(序列化为 JSON) │ │ │ ├─ sessionId: "abc123" │ │ │ ├─ resumeText: "简历文本..." │ │ │ ├─ questionsJson: "[{question: '...', answer: '...'}, ...]"│ │ │ ├─ currentIndex: 5 │ │ │ └─ status: "IN_PROGRESS" │ │ └─ TTL: 24小时 │ ├─────────────────────────────────────────────────────────────────┤ │ interview:resume:{resumeId} │ │ ├─ String 存储 sessionId(用于快速查找未完成会话) │ │ └─ TTL: 24小时 │ └─────────────────────────────────────────────────────────────────┘
断点续面实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @Service public class InterviewSessionCache { public Optional<String> findUnfinishedSessionId (Long resumeId) { String sessionId = redisService.get(RESUME_SESSION_KEY_PREFIX + resumeId); if (sessionId != null ) { return Optional.of(sessionId); } Optional<InterviewSessionEntity> entityOpt = persistenceService.findUnfinishedSession(resumeId); if (entityOpt.isPresent()) { restoreSessionFromEntity(entityOpt.get()); return Optional.of(entityOpt.get().getSessionId()); } return Optional.empty(); } }
面试重点与话术 高频问题
问题
回答要点
“为什么用 Redis 缓存会话?”
性能:答题交互毫秒级;断点续面:24h 内可恢复;削峰:减少数据库压力
“分批评估的具体策略?”
默认每批8题;多轮调用 AI;合并后二次汇总生成整体评价
“如何防止重复提问?”
查询历史问题列表传入 Prompt;AI 生成时明确要求避免重复
“追问机制怎么实现的?”
AI 生成主问题时同时生成追问;转换时展开为线性列表;isFollowUp 标记关联主问题
“提前交卷怎么处理?”
更新状态为 COMPLETED;发送评估任务到 Stream;异步生成报告
亮点数据
技术细节:
缓存TTL: 24小时
分批大小: 每批8题(可配置)
追问数量: 默认1条,最多2条
问题类型: 7大类(项目、MySQL、Redis、Java基础、集合、并发、Spring)
权重分配: 项目20%、MySQL20%、Redis20%、Java基础10%、集合10%、并发10%、Spring10%
可能的追问
Q: 如果 Redis 挂了怎么办?
“有降级策略。每次状态变更都会异步同步到数据库,如果 Redis 不可用,会直接从数据库恢复会话。虽然性能有所下降,但核心功能可用。”
Q: AI 评估失败怎么重试?
“Consumer 层有统一重试机制,最多3次。如果仍失败,标记为 FAILED,用户可以点击’重新生成报告’手动触发。”
Q: 如何控制问题难度?
“Prompt 中传入候选人类型(校招/社招/实习)和目标岗位,AI 会根据这些信息调整问题难度和侧重点。比如校招侧重基础,社招侧重项目和性能优化。”
总结图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ┌─────────────────────────────────────────────────────────────────┐ │ 模拟面试模块技术栈 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 会话管理 Redis 缓存(24h TTL)+ 数据库持久化 │ │ 智能出题 分类权重配比 + 历史去重 + 追问机制 │ │ 答案评估 分批处理(8题/批)+ 二次汇总 │ │ 状态流转 CREATED → IN_PROGRESS → COMPLETED → EVALUATED │ │ 异步处理 Redis Stream Consumer │ │ │ │ 核心亮点: │ │ ✓ 断点续面 ✓ Token溢出防护 ✓ 线性追问流 │ │ ✓ 优雅降级 ✓ 分类权重配比 ✓ 双写一致性 │ │ │ └─────────────────────────────────────────────────────────────────┘
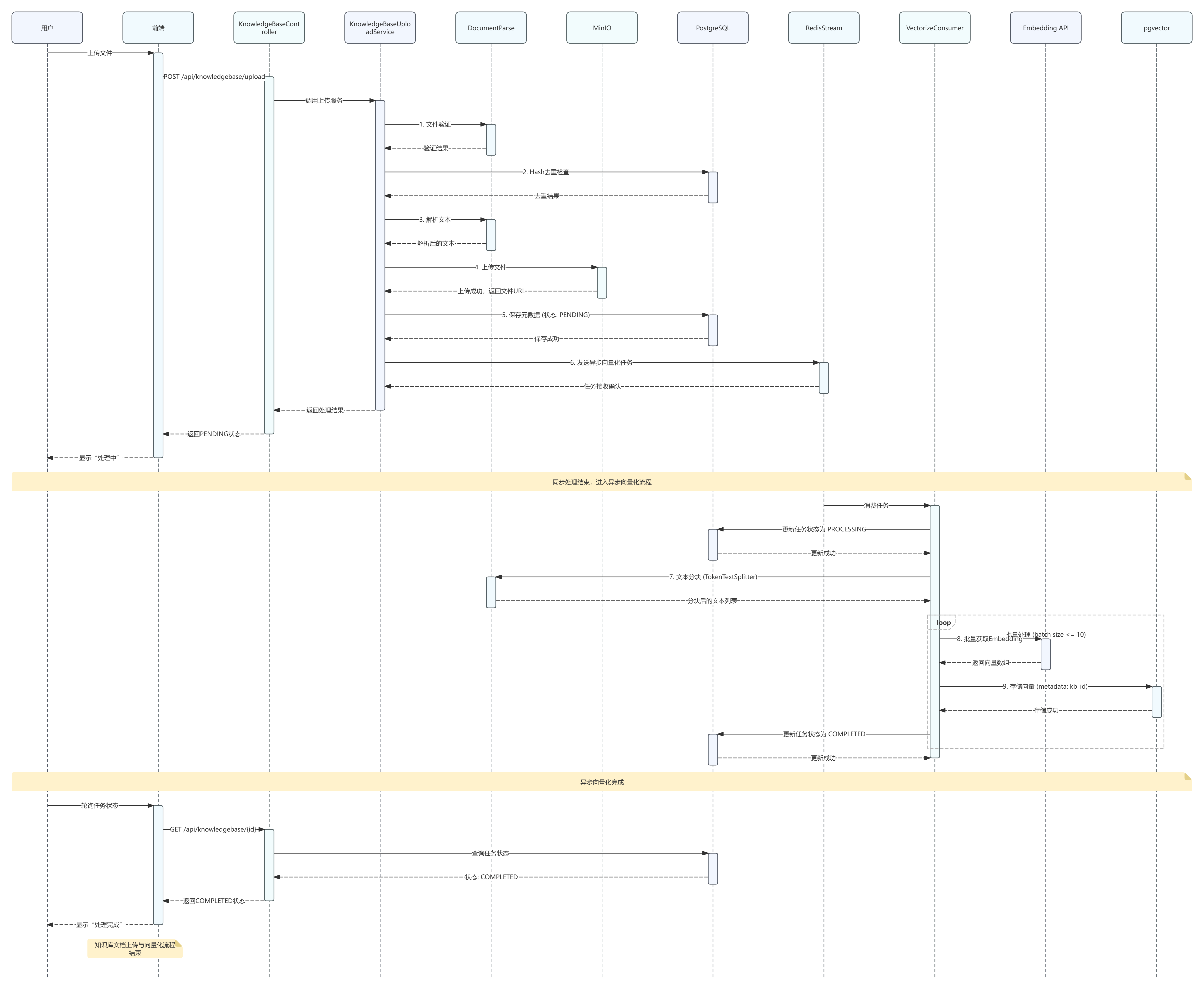
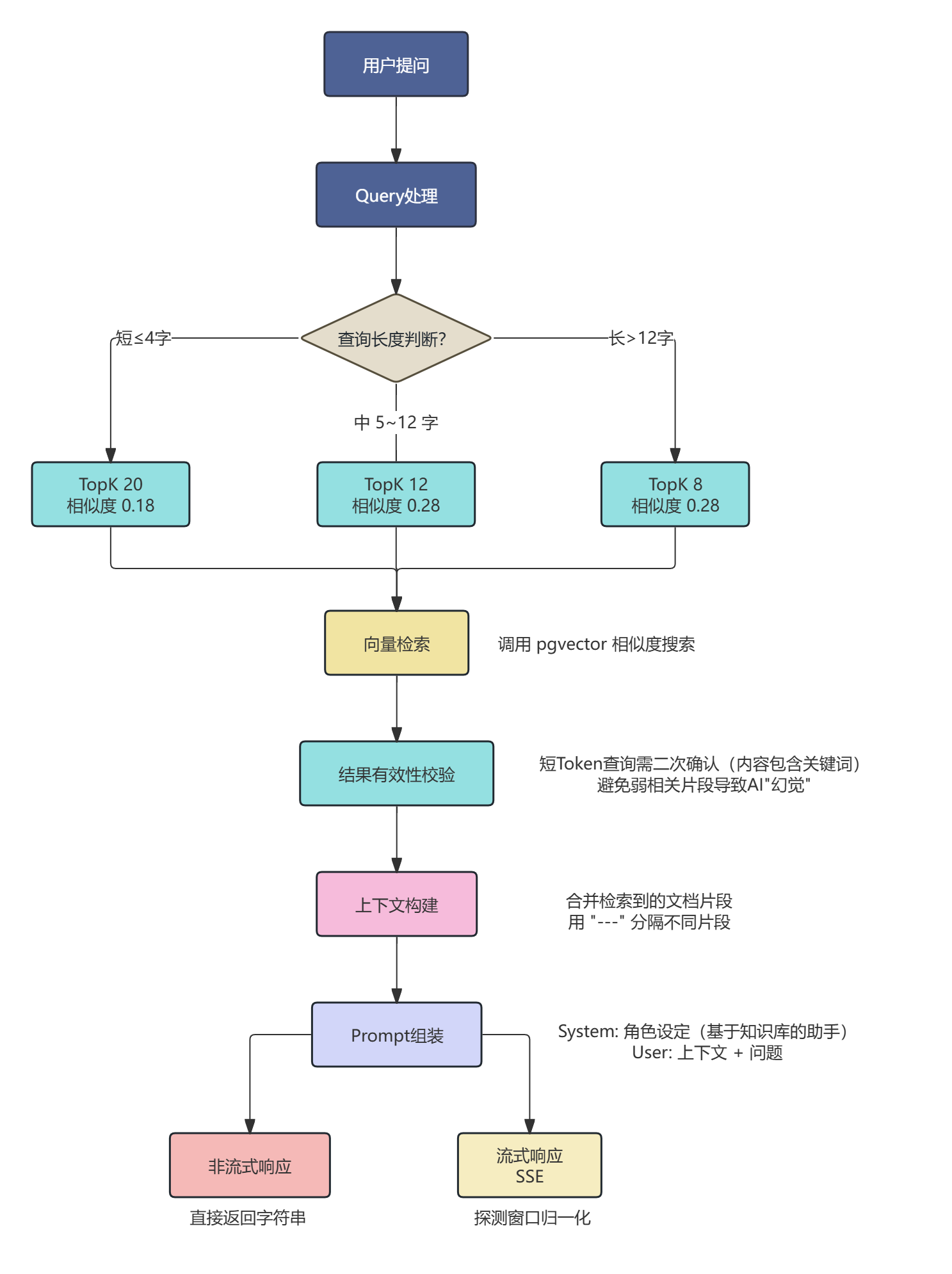
RAG流程 知识库上传与向量化流程 RAG问答流程 关键技术实现(面试重点 ★★★) 文本分块与向量化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @Service public class KnowledgeBaseVectorService { private static final int MAX_BATCH_SIZE = 10 ; private final VectorStore vectorStore; private final TextSplitter textSplitter; public KnowledgeBaseVectorService (VectorStore vectorStore, ...) { this .vectorStore = vectorStore; this .textSplitter = new TokenTextSplitter (); } @Transactional public void vectorizeAndStore (Long knowledgeBaseId, String content) { deleteByKnowledgeBaseId(knowledgeBaseId); List<Document> chunks = textSplitter.apply(List.of(new Document (content))); chunks.forEach(chunk -> chunk.getMetadata().put("kb_id" , knowledgeBaseId.toString()) ); int batchCount = (totalChunks + MAX_BATCH_SIZE - 1 ) / MAX_BATCH_SIZE; for (int i = 0 ; i < batchCount; i++) { List<Document> batch = chunks.subList(start, end); vectorStore.add(batch); } } }
面试话术:
“文本分块使用 TokenTextSplitter,设置每块约 500 tokens、重叠 50 tokens。重叠设计是为了避免关键信息被截断在边界。
RAG 检索优化 —— 动态参数 + Query Rewrite1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 @Service public class KnowledgeBaseQueryService { @Value("${app.ai.rag.search.short-query-length:4}") private int shortQueryLength; @Value("${app.ai.rag.search.topk-short:20}") private int topkShort; @Value("${app.ai.rag.search.topk-medium:12}") private int topkMedium; @Value("${app.ai.rag.search.topk-long:8}") private int topkLong; @Value("${app.ai.rag.search.min-score-short:0.18}") private double minScoreShort; @Value("${app.ai.rag.search.min-score-default:0.28}") private double minScoreDefault; private QueryContext buildQueryContext (String originalQuestion) { String normalizedQuestion = normalizeQuestion(originalQuestion); String rewrittenQuestion = rewriteQuestion(normalizedQuestion); Set<String> candidates = new LinkedHashSet <>(); candidates.add(rewrittenQuestion); candidates.add(normalizedQuestion); SearchParams searchParams = resolveSearchParams(normalizedQuestion); return new QueryContext (normalizedQuestion, new ArrayList <>(candidates), searchParams); } private SearchParams resolveSearchParams (String question) { int compactLength = question.replaceAll("\\s+" , "" ).length(); if (compactLength <= shortQueryLength) { return new SearchParams (topkShort, minScoreShort); } if (compactLength <= 12 ) { return new SearchParams (topkMedium, minScoreDefault); } return new SearchParams (topkLong, minScoreDefault); } private String rewriteQuestion (String question) { if (!rewriteEnabled || question.isBlank()) { return question; } String rewritePrompt = rewritePromptTemplate.render(variables); String rewritten = aiChatClientFactory.getChatClient().prompt() .user(rewritePrompt) .call() .content(); log.info("Query rewrite: origin='{}', rewritten='{}'" , question, normalized); return normalized; } }
面试亮点:
动态参数 :短查询用更高的 TopK 和更低的相似度阈值,提高召回率;长查询则更严格,减少噪音Query Rewrite :短查询(如”Redis”)语义模糊,通过 AI 扩展为”Redis 的数据结构和常用命令有哪些”,提高检索质量多候选查询 :原查询和重写查询都尝试检索,取第一个有效结果
检索结果有效性校验 —— 避免 AI “幻觉”1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @Service public class KnowledgeBaseQueryService { private boolean hasEffectiveHit (String question, List<Document> docs) { if (docs == null || docs.isEmpty()) { return false ; } if (!isShortTokenQuery(normalized)) { return true ; } String loweredToken = normalized.toLowerCase(); for (Document doc : docs) { String text = doc.getText(); if (text != null && text.toLowerCase().contains(loweredToken)) { return true ; } } log.info("短 query 命中确认失败,视为无有效结果" ); return false ; } private boolean isShortTokenQuery (String question) { return SHORT_TOKEN_PATTERN.matcher(compact).matches(); } }
面试话术:
“向量相似度高的结果不一定真的相关。比如查询’Redis’,可能返回一个提到’缓存策略’的段落,向量距离很近,但实际没有 Redis 的具体信息。
流式响应优化 —— 探测窗口归一化1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 @Service public class KnowledgeBaseQueryService { private static final int STREAM_PROBE_CHARS = 120 ; private Flux<String> normalizeStreamOutput (Flux<String> rawFlux) { return Flux.create(sink -> { StringBuilder probeBuffer = new StringBuilder (); AtomicBoolean passthrough = new AtomicBoolean (false ); rawFlux.subscribe( chunk -> { if (passthrough.get()) { sink.next(chunk); return ; } probeBuffer.append(chunk); String probeText = probeBuffer.toString(); if (isNoResultLike(probeText)) { sink.next(NO_RESULT_RESPONSE); sink.complete(); return ; } if (probeBuffer.length() >= STREAM_PROBE_CHARS) { passthrough.set(true ); sink.next(probeText); } }, sink::error, () -> { if (!passthrough.get()) { sink.next(normalizeAnswer(probeBuffer.toString())); } sink.complete(); } ); }); } private boolean isNoResultLike (String text) { return text.contains("没有找到相关信息" ) || text.contains("未检索到相关信息" ) || text.contains("信息不足" ) || text.contains("无法根据提供内容回答" ); } }
面试话术:
“流式响应有一个痛点:如果检索结果不足,AI 可能会输出大段’抱歉,我没有找到相关信息…’,用户要看完这段话才知道没结果,体验很差。
多知识库联合检索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @Service public class KnowledgeBaseVectorService { public List<Document> similaritySearch (String query, List<Long> knowledgeBaseIds, int topK, double minScore) { SearchRequest.Builder builder = SearchRequest.builder() .query(query) .topK(Math.max(topK, 1 )); if (minScore > 0 ) { builder.similarityThreshold(minScore); } if (knowledgeBaseIds != null && !knowledgeBaseIds.isEmpty()) { builder.filterExpression(buildKbFilterExpression(knowledgeBaseIds)); } return vectorStore.similaritySearch(builder.build()); } private String buildKbFilterExpression (List<Long> knowledgeBaseIds) { String values = knowledgeBaseIds.stream() .map(String::valueOf) .map(id -> "'" + id + "'" ) .collect(Collectors.joining(", " )); return "kb_id in [" + values + "]" ; } }
面试话术:
“系统支持多知识库联合检索,用户可以同时选择多个知识库进行问答。实现方式是在向量检索时添加 filter 表达式 kb_id in [‘1’, ‘2’],只检索指定知识库的向量。
RAG 多轮对话 —— 会话管理1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 @Service public class RagChatSessionService { @Transactional public Long prepareStreamMessage (Long sessionId, String question) { RagChatMessageEntity userMessage = new RagChatMessageEntity (); userMessage.setType(MessageType.USER); userMessage.setContent(question); userMessage.setCompleted(true ); messageRepository.save(userMessage); RagChatMessageEntity assistantMessage = new RagChatMessageEntity (); assistantMessage.setType(MessageType.ASSISTANT); assistantMessage.setContent("" ); assistantMessage.setCompleted(false ); assistantMessage = messageRepository.save(assistantMessage); return assistantMessage.getId(); } @Transactional public void completeStreamMessage (Long messageId, String content) { RagChatMessageEntity message = messageRepository.findById(messageId) .orElseThrow(...); message.setContent(content); message.setCompleted(true ); messageRepository.save(message); } public Flux<String> getStreamAnswer (Long sessionId, String question) { RagChatSessionEntity session = sessionRepository .findByIdWithKnowledgeBases(sessionId) .orElseThrow(...); List<Long> kbIds = session.getKnowledgeBaseIds(); return queryService.answerQuestionStream(kbIds, question); } }
面试话术:
“RAG 多轮对话的实现关键是消息状态管理。用户发送问题时,我同步保存两条消息:用户消息(completed=true)和 AI 消息占位(completed=false)。
面试重点与话术 高频问题
问题
回答要点
“为什么用 pgvector 而不是专用向量数据库?”
架构精简,不引入新组件;PG 的向量功能已满足需求;事务一致性(向量和业务数据在一个数据库)
“文本分块的策略是什么?”
TokenTextSplitter,每块 500 tokens,重叠 50 tokens;重叠保持语义连贯
“Query Rewrite 的作用?”
短查询语义模糊,通过 AI 扩展为更具体的查询,提高召回率
“如何处理检索不到结果的情况?”
探测窗口识别无信息模板;有效性校验(短查询二次确认);优雅降级返回固定提示
“多知识库检索怎么实现?”
filter 表达式 kb_id in […];Spring AI SearchRequest 支持过滤条件
亮点数据
技术细节:
向量维度: 1024 (text-embedding-v3)
分块大小: 500 tokens / 块
重叠大小: 50 tokens
批量限制: 10 chunks / 批 (Embedding API 限制)
动态TopK: 短查询 20, 中查询 12, 长查询 8
相似度阈值: 短查询 0.18, 其他 0.28
探测窗口: 120 字符 (流式优化)
响应方式: 非流式 + SSE 流式双支持
可能的追问
Q: 向量检索失败怎么办?
“有 fallback 机制。如果带过滤条件的检索失败(可能是表达式语法问题),会降级到全量检索,然后在内存中过滤 kb_id,保证功能可用性。”
Q: 如何更新已上传的知识库?
“支持重新向量化 API。删除旧向量,重新解析文件并生成新向量。设计上保证幂等性,可以安全地多次执行。”
Q: 流式响应中断怎么处理?
“通过 doOnError 捕获异常,保存已接收的内容到数据库,并标记消息状态。用户刷新页面后可以看到已生成的部分内容。”
总结图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ┌─────────────────────────────────────────────────────────────────┐ │ 知识库 + RAG 模块技术栈 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 文档处理 Apache Tika (PDF/DOCX/MD/TXT) │ │ 文本分块 TokenTextSplitter (500 tokens/chunk) │ │ 向量化 text-embedding-v3 (1024维) │ │ 向量存储 PostgreSQL + pgvector (HNSW索引) │ │ RAG检索 Spring AI VectorStore + 相似度搜索 │ │ │ │ 优化策略: │ │ ✓ Query Rewrite ✓ 动态检索参数 ✓ 短Query二次确认 │ │ ✓ 多知识库联合检索 ✓ 探测窗口归一化 ✓ 流式/SSE双模式 │ │ │ │ 状态流转: PENDING → PROCESSING → COMPLETED/FAILED │ │ │ └─────────────────────────────────────────────────────────────────┘
其他 AI 配置管理 一句话概括
“考虑到不同 AI 平台的成本和效果差异,我设计了一套配置驱动的多平台适配方案,支持在阿里云 DashScope、Moonshot、DeepSeek 之间动态切换,无需重启服务。”
技术实现要点(4个维度)
维度
实现方式
亮点
配置存储 PostgreSQL 持久化 + AES 加密 API Key
安全、可动态更新
工厂模式 AiChatClientFactory 统一创建 ChatClient
封装不同平台的 BaseUrl、默认模型差异
动态加载 运行时从 DB 读取配置创建客户端
无需重启,即时生效
兼容封装 Spring AI 的 OpenAI 兼容模式
一套代码适配多平台
代码亮点说明
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 if ("moonshot" .equalsIgnoreCase(provider) && modelName.startsWith("kimi-k2.5" )) { } else { optionsBuilder.temperature(temperature); } public ChatClient getChatClient () { if (dbConfig.isPresent()) { return buildChatClient(dbConfig.get()); } return defaultChatClientBuilder.build(); }
📝 更新后的电梯演讲(增加这一段)
在技术亮点部分插入:
“多AI平台动态适配。考虑到不同平台的成本和效果差异,我设计了配置驱动的工厂模式,支持阿里云 DashScope、Moonshot、DeepSeek 等平台动态切换,API Key 使用 AES 加密存储,配置变更无需重启服务即可生效。这样可以根据业务场景灵活选择模型,比如在需要深度推理时切换到 DeepSeek,日常对话使用轻量级模型降低成本。”
🎯 可能的追问 & 应对
追问
回答要点
“为什么不用配置文件而用数据库?”
配置变更无需重启;支持多租户/多用户场景;便于前端管理界面配置
“如何防止 API Key 泄露?”
AES 加密存储;接口返回时脱敏;前端展示时隐藏真实 Key
“不同平台的模型特性差异如何处理?”
工厂类内置默认模型映射;特殊参数(如 kimi-k2.5 的 temperature)做兼容处理
“如果要加新平台(比如 OpenAI)要改多少代码?”
只需在工厂类添加 BaseUrl 和默认模型,符合开闭原则
我来读取完整文件内容,确保转换完整:
文件内容已经是 Markdown 格式 ,以下是完整的文档内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 # 2.2 核心实现 ```java @Component public class AiChatClientFactory { private final AiConfigService aiConfigService; // 默认配置(从环境变量读取) @Value("${spring.ai.openai.api-key}") private String defaultApiKey; @Value("${spring.ai.openai.chat.options.model:qwen-plus}") private String defaultModel; /** * 获取ChatClient(优先使用DB配置,降级到默认配置) */ public ChatClient getChatClient() { Optional<AiConfigEntity> configOpt = aiConfigService.getAiConfig(); if (configOpt.isPresent()) { AiConfigEntity config = configOpt.get(); return buildChatClient( config.getProvider(), AesEncryptionUtils.decrypt(config.getEncryptedApiKey()), config.getModelName(), config.getTemperature(), config.getTopP() ); } // 降级到默认配置 return defaultChatClientBuilder.build(); } /** * 构建指定平台的ChatClient */ public ChatClient buildChatClient(String provider, String apiKey, String modelName, Double temperature, Double topP) { // 1. 确定BaseUrl String baseUrl = getBaseUrlByProvider(provider); // 2. 参数兜底 if (apiKey == null || apiKey.isEmpty()) { apiKey = defaultApiKey; } if (modelName == null || modelName.isEmpty()) { modelName = getDefaultModelByProvider(provider); } // 3. 构建OpenAiApi(Spring AI的兼容模式) OpenAiApi openAiApi = OpenAiApi.builder() .baseUrl(baseUrl) .apiKey(apiKey) .completionsPath("/chat/completions") .restClientBuilder(RestClient.builder() .requestFactory(new SimpleClientHttpRequestFactory() {{ setConnectTimeout((int) Duration.ofSeconds(60).toMillis()); setReadTimeout((int) Duration.ofMinutes(5).toMillis()); }})) .build(); // 4. 特殊参数处理(Moonshot kimi-k2.5对temperature敏感) OpenAiChatOptions.Builder optionsBuilder = OpenAiChatOptions.builder() .model(modelName); if ("moonshot".equalsIgnoreCase(provider) && modelName != null && modelName.startsWith("kimi-k2.5")) { // kimi-k2.5 特殊处理:不设置temperature避免报错 } else { if (temperature != null) optionsBuilder.temperature(temperature); if (topP != null) optionsBuilder.topP(topP); } // 5. 构建ChatModel和ChatClient ChatModel chatModel = OpenAiChatModel.builder() .openAiApi(openAiApi) .defaultOptions(optionsBuilder.build()) .build(); return ChatClient.builder(chatModel).build(); } private String getBaseUrlByProvider(String provider) { return switch (provider.toLowerCase()) { case "moonshot" -> "https://api.moonshot.cn/v1"; case "deepseek" -> "https://api.deepseek.com/v1"; default -> "https://dashscope.aliyuncs.com/compatible-mode/v1"; }; } }
面试话术:
“多AI平台适配采用工厂模式设计,核心思想是配置驱动 + 统一封装。
配置化、安全化 限流组件 —— Redis + Lua 滑动窗口 架构设计 @RateLimit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 ┌─────────────────────────────────────────────────────────────────┐ │ 限流组件架构图 │ ├─────────────────────────────────────────────────────────────────┤ │ │ │ 使用方式(注解式,零侵入) │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ @PostMapping("/api/resumes/upload") │ │ │ │ @RateLimit( │ │ │ │ dimensions = {GLOBAL, IP}, // 多维度组合 │ │ │ │ count = 5, // 5次 │ │ │ │ interval = 1, // 1分钟 │ │ │ │ timeUnit = TimeUnit.MINUTES │ │ │ │ ) │ │ │ │ public Result<?> upload(...) {...} │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ │ │ ▼ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ RateLimitAspect (AOP切面) │ │ │ │ ├─ 解析注解参数 │ │ │ │ ├─ 生成限流Key(支持Hash Tag适配Cluster) │ │ │ │ ├─ 调用Lua脚本(原子性检查+扣减) │ │ │ │ └─ 触发降级策略(抛出异常或调用fallback方法) │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ │ │ ▼ │ │ ┌─────────────────────────────────────────────────────────┐ │ │ │ rate_limit.lua (Redis脚本) │ │ │ │ │ │ │ │ Phase 1: 预检查(检查所有维度配额) │ │ │ │ FOR each key: │ │ │ │ - 清理过期令牌(滑动窗口) │ │ │ │ - 检查 current_val >= permits │ │ │ │ - 任一维度不足 → RETURN 0 │ │ │ │ │ │ │ │ Phase 2: 扣减(只有全部通过才执行) │ │ │ │ FOR each key: │ │ │ │ - 记录 permit (ZADD) │ │ │ │ - 扣减令牌 (DECR) │ │ │ │ RETURN 1 │ │ │ │ │ │ │ └─────────────────────────────────────────────────────────┘ │ │ │ │ Redis 数据结构: │ │ ├─ {Class:Method}:global:value - 全局限流计数器 │ │ ├─ {Class:Method}:global:permits - 全局限流记录(Sorted Set) │ │ ├─ {Class:Method}:ip:{ip}:value - IP限流计数器 │ │ └─ {Class:Method}:ip:{ip}:permits - IP限流记录 │ │ │ │ Hash Tag {} 确保同一方法的所有Key落在同一Redis Slot │ │ │ └─────────────────────────────────────────────────────────────────┘
Lua 脚本详解(滑动窗口算法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 local now_ms = tonumber (ARGV[1 ]) local permits = tonumber (ARGV[2 ]) local interval = tonumber (ARGV[3 ]) local max_tokens = tonumber (ARGV[4 ]) local request_id = ARGV[5 ] for i, key in ipairs (KEYS) do local value_key = key .. ":value" local permits_key = key .. ":permits" if redis.call("exists" , value_key) == 0 then redis.call("set" , value_key, max_tokens) end local expired_values = redis.call("zrangebyscore" , permits_key, 0 , now_ms - interval) if #expired_values > 0 then local expired_count = 0 for _, v in ipairs (expired_values) do local p = tonumber (string .match (v, ":(%d+)$" )) if p then expired_count = expired_count + p end end redis.call("zremrangebyscore" , permits_key, 0 , now_ms - interval) if expired_count > 0 then local curr_v = tonumber (redis.call("get" , value_key) or max_tokens) local next_v = math .min (max_tokens, curr_v + expired_count) redis.call("set" , value_key, next_v) end end local current_val = tonumber (redis.call("get" , value_key) or max_tokens) if current_val < permits then return 0 end end for i, key in ipairs (KEYS) do local value_key = key .. ":value" local permits_key = key .. ":permits" local permit_record = request_id .. ":" .. permits redis.call("zadd" , permits_key, now_ms, permit_record) local current_v = tonumber (redis.call("get" , value_key) or max_tokens) redis.call("set" , value_key, current_v - permits) local expire_time = math .ceil (interval * 2 / 1000 ) redis.call("expire" , value_key, expire_time) redis.call("expire" , permits_key, expire_time) end return 1
面试话术:
“限流组件主要用在 AI 调用密集型 和 资源消耗型 接口上:
简历模块:上传和重新分析接口,限制每 IP 每分钟 2-5 次,防止恶意刷 AI 分析配额。
面试模块:创建面试(AI 出题)限制 5 次/分钟,提交答案限制 10 次/分钟。
知识库模块:上传(3 次/分钟)、重新向量化(2 次/分钟)、RAG 问答(10 次/分钟)、流式问答(5 次/分钟)。
设计原则:AI 调用越贵、资源消耗越大、连接占用越长,限制越严格。使用 GLOBAL + IP 双维度,既防止单用户刷接口,又防止全局过载。”
限流组件基于 Redis + Lua 实现滑动时间窗口算法,保证原子性。
双Key结构:value存储当前可用令牌数,permits(Sorted Set)存储历史请求时间戳
滑动窗口:每次请求时清理窗口外的过期记录,并返还配额,相比固定窗口更平滑
多维度组合:支持 GLOBAL、IP、USER 多维度同时限流,只有所有维度通过才放行
Hash Tag:Key使用 {class:method} 包含Hash Tag,确保Redis Cluster模式下同一Slot
结构化输出调用器 —— 带重试机制 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 @Component public class StructuredOutputInvoker { private static final String STRICT_JSON_INSTRUCTION = """ 请仅返回可被 JSON 解析器直接解析的 JSON 对象,并严格满足字段结构要求: 1) 不要输出 Markdown 代码块(如 ```json)。 2) 不要输出任何解释文字、前后缀、注释。 3) 所有字符串内引号必须正确转义。 """ ; private final int maxAttempts; public <T> T invoke ( ChatClient chatClient, String systemPromptWithFormat, // 包含JSON Schema的System Prompt String userPrompt, BeanOutputConverter<T> outputConverter, // Spring AI的结构化转换器 ErrorCode errorCode, // 业务错误码 String errorPrefix, // 错误前缀 String logContext, // 日志上下文 Logger log ) { Exception lastError = null ; for (int attempt = 1 ; attempt <= maxAttempts; attempt++) { String attemptSystemPrompt = (attempt == 1 ) ? systemPromptWithFormat : buildRetrySystemPrompt(systemPromptWithFormat, lastError); try { return chatClient.prompt() .system(attemptSystemPrompt) .user(userPrompt) .call() .entity(outputConverter); } catch (Exception e) { lastError = e; log.warn("{}结构化解析失败,准备重试: attempt={}, error={}" , logContext, attempt, e.getMessage()); } } throw new BusinessException (errorCode, errorPrefix + lastError.getMessage()); } private String buildRetrySystemPrompt (String originalPrompt, Exception lastError) { return originalPrompt + "\n\n" + STRICT_JSON_INSTRUCTION + "\n上次输出解析失败,请仅返回合法 JSON。" + "\n上次失败原因:" + sanitizeErrorMessage(lastError.getMessage()); } }
面试话术:
“大模型返回结构化JSON时,可能出现格式问题(加了Markdown代码块、缺少引号、多了注释等)。
第一次使用标准Prompt
如果解析失败,第二次在Prompt中追加 Strict JSON Instruction,明确要求不输出Markdown、不输出解释文字、正确转义引号
同时把上次的错误信息反馈给模型,帮助其修正
AES 加密工具 —— API Key 安全存储 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class AesEncryptionUtils { private static final String ALGORITHM = "AES" ; private static final String DEFAULT_KEY = "OfferFlowSecKey1" ; public static String encrypt (String value) { if (value == null || value.isEmpty()) return value; SecretKeySpec key = new SecretKeySpec ( DEFAULT_KEY.getBytes(StandardCharsets.UTF_8), ALGORITHM ); Cipher cipher = Cipher.getInstance(ALGORITHM); cipher.init(Cipher.ENCRYPT_MODE, key); byte [] encrypted = cipher.doFinal(value.getBytes(StandardCharsets.UTF_8)); return Base64.getEncoder().encodeToString(encrypted); } public static String decrypt (String encryptedValue) { if (encryptedValue == null || encryptedValue.isEmpty()) return encryptedValue; SecretKeySpec key = new SecretKeySpec ( DEFAULT_KEY.getBytes(StandardCharsets.UTF_8), ALGORITHM ); Cipher cipher = Cipher.getInstance(ALGORITHM); cipher.init(Cipher.DECRYPT_MODE, key); byte [] original = cipher.doFinal( Base64.getDecoder().decode(encryptedValue) ); return new String (original, StandardCharsets.UTF_8); } }
面试话术:
“AI平台的API Key是敏感信息,需要加密存储。我实现了AES对称加密工具:
使用AES算法,128位密钥(16字节)
加密后Base64编码存储到数据库
使用时解密后内存中使用,不落盘
面试重点与话术 高频问题
问题
回答要点
“限流为什么选择 Redis + Lua?”
原子性:Lua脚本在Redis单线程执行,避免竞态;性能:内存操作,毫秒级;灵活性:支持多维度组合和动态参数
“滑动窗口和固定窗口的区别?”
固定窗口在边界可能突发2倍流量;滑动窗口持续清理过期记录,更平滑;实现稍复杂,需要记录时间戳
“多AI平台适配怎么保证兼容性?”
Spring AI的OpenAI兼容模式统一封装;工厂类处理平台差异(BaseUrl、默认模型、特殊参数);配置驱动,动态切换
“API Key加密怎么做的?”
AES对称加密,Base64存储;读取时解密使用;前端展示脱敏;生产环境建议用KMS
“结构化输出失败怎么办?”
最多2次重试;第二次Prompt追加Strict JSON指令;反馈错误信息给模型;最终失败抛业务异常
亮点数据
技术细节:
限流算法: 滑动时间窗口
限流维度: GLOBAL, IP, USER(可组合)
Lua脚本: 两阶段(预检查+扣减),保证原子性
重试机制: 最多2次,指数退避
加密算法: AES-128,Base64编码
支持平台: 阿里云DashScope, Moonshot, DeepSeek(可扩展)
可能的追问
Q: 限流组件支持分布式吗?
“支持。Redis本身就是分布式存储,配合Hash Tag确保同一方法的所有Key在同一Slot,Cluster模式下也能正常工作。如果需要更高可用,可以用Redis Sentinel或Cluster模式。”
Q: 如果要加新的AI平台(比如OpenAI)需要改多少代码?
“只需在 AiChatClientFactory 添加新的BaseUrl映射和默认模型,符合开闭原则。如果平台有特殊参数要求,在 buildChatClient 中添加对应的特殊处理逻辑即可。”Q: 限流降级怎么做
“@RateLimit 注解支持 fallback 参数指定降级方法。如果限流触发,会优先调用降级方法;如果没有配置或降级失败,抛出 RateLimitExceededException,由全局异常处理器返回友好提示。”